Visão Geral
Os pipelines de transformação de dados são responsáveis por transitar os dados para além da camada bronze (etapa staging):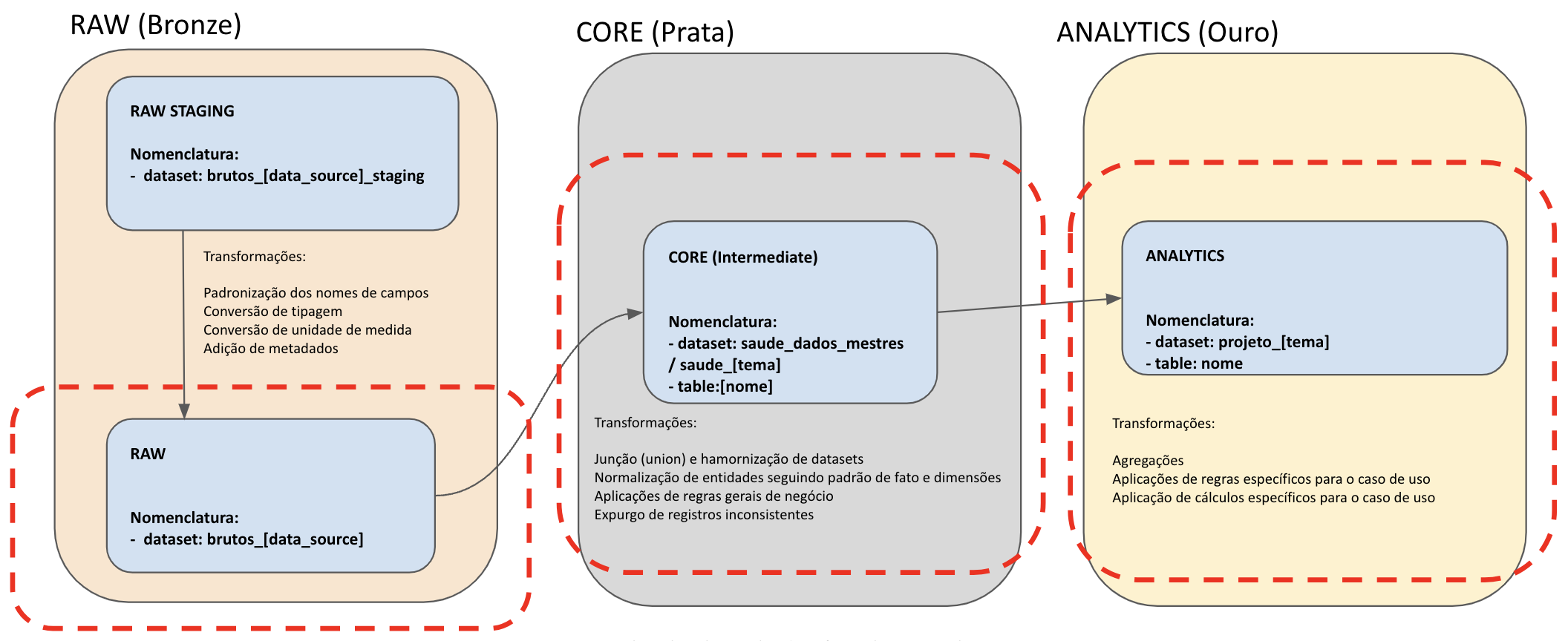
Modelos de Dados - IplanRio
Repositório com os modelos de dados desenvolvidos pela IplanRio.
Conhecimentos Necessários
Para desenvolver um pipeline de transformação de dados, é necessário os seguintes conhecimentos:- Linguagem SQL para transformar os dados nos formatos das camadas seguintes.
- Versionamento de código em Git.
- Ferramenta dbt para realizar a materialização das tabelas dentro do BigQuery.
Onde Aprender
SQL
Como em qualquer SGBD, a sintaxe SQL utilizada no BigQuery possui suas particularidades e funções específicas. Para conhecer mais, recomendamos utilizar a documentação oficial do GoogleSQL.dbt
Para aprender a trabalhar com o dbt, indicamos consumir os treinamentos oficiais da empresa que desenvolve a solução:Curso introdutório - dbt Learn
Curso introdutório ao dbt, com foco em modelagem de dados e boas práticas.
Escrevendo SQL modular - dbt Learn
Curso sobre boas práticas de escrita de SQL, com foco em modularização e reutilização de código.
Métodos avançados para testar seus pipelines - dbt Learn
Curso sobre boas práticas de testes em pipelines, com foco em testes automatizados e explicandos os diferentes testes no DBT.