Visão Geral
Os pipelines de Extração e Carga de dados são responsáveis por levar os dados até a primeira camada de dados dentro do BigQuery, a camada bronze (etapa staging):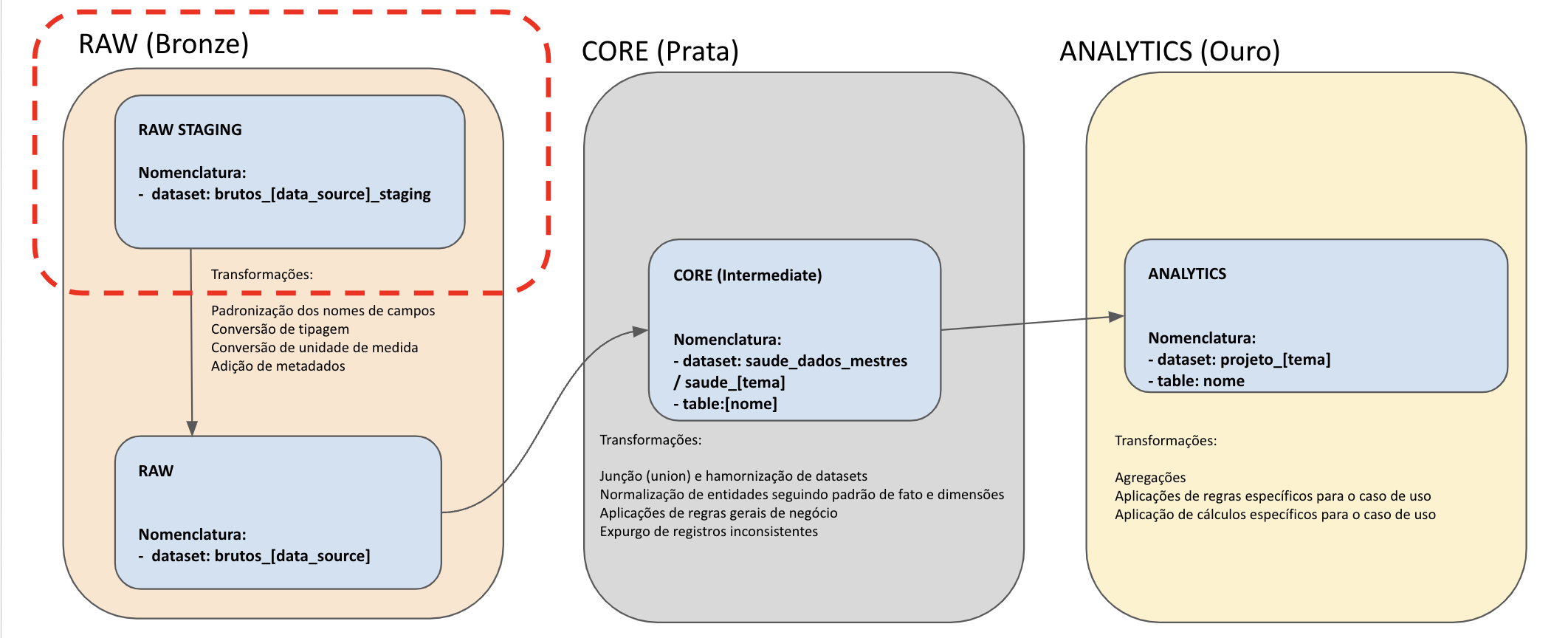
Conhecimentos Necessários
Para desenvolver um pipeline de extração e carga de dados, é necessário os seguintes conhecimentos:- Linguagem Python para montar os scripts de extração e carga.
- Versionamento de código em Git.
- Ferramenta Prefect para orquestração dos scripts Python.
Onde Aprender
Para aprender a extrair e carregar os dados no Data Lake, consulte:- Criação de Pipelines — passo a passo para construir um novo pipeline
- Prefect: Construindo uma Pipeline — configuração e deploy no Prefect
- Repositório pipelines_rj_sms — exemplos de pipelines de saúde (SMS)
- Repositório prefect_rj_iplanrio — pipelines gerais da IplanRio